library(nycflights13)
library(tidyverse)
summarize(flights, mean_sched_dep_time = mean(sched_dep_time))# A tibble: 1 × 1
mean_sched_dep_time
<dbl>
1 1344.2024-05-07
データが手に入る時、まだ解析に使いえない状態が多い
データの整理(「wrangling」)は解析に使えるように整えるプロセス
Getty Images
Image by Allison Horst
summarize()でデータの集計ができる:
しかし、全体の平均だけを計算してもあまり意味はない。
それよりも、何か毎にデータの集計を行いたい方が多い。
それにはgroup_by()関数を使う。例えば、月ごと。まずはデータのグループを指定する:
# A tibble: 336,776 × 19
# Groups: month [12]
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# ℹ 336,766 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
# carrier <chr>, flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>次に、集計する:
あれ?なんでNAになってしまった?
NA(「Not Applicable」、「該当しない」)はデータが欠けていることを示す。mean()は一つでもデータが欠けていることがあると、結果は全部NAになってしまう。na.rm = TRUEを指定しないといけないNAだったのかをfilter()で確かめる# A tibble: 8,255 × 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 NA 1630 NA NA
2 2013 1 1 NA 1935 NA NA
3 2013 1 1 NA 1500 NA NA
4 2013 1 1 NA 600 NA NA
5 2013 1 2 NA 1540 NA NA
6 2013 1 2 NA 1620 NA NA
7 2013 1 2 NA 1355 NA NA
8 2013 1 2 NA 1420 NA NA
9 2013 1 2 NA 1321 NA NA
10 2013 1 2 NA 1545 NA NA
# ℹ 8,245 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
# carrier <chr>, flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>n()でグループの件数を数える# A tibble: 12 × 3
month avg_delay n
<int> <dbl> <int>
1 1 10.0 27004
2 2 10.8 24951
3 3 13.2 28834
4 4 13.9 28330
5 5 13.0 28796
6 6 20.8 28243
7 7 21.7 29425
8 8 12.6 29327
9 9 6.72 27574
10 10 6.24 28889
11 11 5.44 27268
12 12 16.6 28135ungroup()でグループを解除するungroup()でグループの解除をする必要がある場合がある。(以下のコードでは自動的にグループが解除されるので本当はいらないけど、必要な場合もある)
ungroup()でグループを解除する同じデータを様々な形で表すことができる。
例えば、以下の結核のデータを見ましょう(tidyverseのtidyrパッケージに入っている例のデータセット):
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583元々のデータが同じであることは確認できましたか?
でも、table1とtable2には大事な違いがある:
table1だけがtidy(すぐに解析できるように整っている)になっているmutate()、filter()など)はtidyなデータの方が使いやすい例えば:
# A tibble: 6 × 5
country year cases population rate
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071 0.373
2 Afghanistan 2000 2666 20595360 1.29
3 Brazil 1999 37737 172006362 2.19
4 Brazil 2000 80488 174504898 4.61
5 China 1999 212258 1272915272 1.67
6 China 2000 213766 1280428583 1.67 billboardというデータセットには2000年の歌のランキングが入っている:
# A tibble: 317 × 79
artist track date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7
<chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 Pac Baby… 2000-02-26 87 82 72 77 87 94 99
2 2Ge+h… The … 2000-09-02 91 87 92 NA NA NA NA
3 3 Doo… Kryp… 2000-04-08 81 70 68 67 66 57 54
4 3 Doo… Loser 2000-10-21 76 76 72 69 67 65 55
5 504 B… Wobb… 2000-04-15 57 34 25 17 17 31 36
6 98^0 Give… 2000-08-19 51 39 34 26 26 19 2
7 A*Tee… Danc… 2000-07-08 97 97 96 95 100 NA NA
8 Aaliy… I Do… 2000-01-29 84 62 51 41 38 35 35
9 Aaliy… Try … 2000-03-18 59 53 38 28 21 18 16
10 Adams… Open… 2000-08-26 76 76 74 69 68 67 61
# ℹ 307 more rows
# ℹ 69 more variables: wk8 <dbl>, wk9 <dbl>, wk10 <dbl>, wk11 <dbl>,
# wk12 <dbl>, wk13 <dbl>, wk14 <dbl>, wk15 <dbl>, wk16 <dbl>,
# wk17 <dbl>, wk18 <dbl>, wk19 <dbl>, wk20 <dbl>, wk21 <dbl>,
# wk22 <dbl>, wk23 <dbl>, wk24 <dbl>, wk25 <dbl>, wk26 <dbl>,
# wk27 <dbl>, wk28 <dbl>, wk29 <dbl>, wk30 <dbl>, wk31 <dbl>,
# wk32 <dbl>, wk33 <dbl>, wk34 <dbl>, wk35 <dbl>, wk36 <dbl>, …billboardartist アーティスト(演奏者)track 曲名date.entered 最初にランキングに入った日付wk1 .. wk76 それぞれの種のランキング列がやたらある。そして、列の名前にデータがある(周目)。これをどうやって別の変数にできるのでしょうか?
pivot_longer()pivot_longer()の主な引数:
cols どの列を使う(ロングにする)names_to ロング形式に変換される新しい列の名前values_to 新しい値の列の名前でや、やって見ましょう
# A tibble: 24,092 × 5
artist track date.entered week rank
<chr> <chr> <date> <chr> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
8 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk8 NA
9 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk9 NA
10 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk10 NA
# ℹ 24,082 more rows列の数が大幅に減り、行の数が増えたことが分かりますか?
cms_patient_experienceというデータセットには患者の経験のデータが入っている
# A tibble: 500 × 5
org_pac_id org_nm measure_cd measure_title prf_rate
<chr> <chr> <chr> <chr> <dbl>
1 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 63
2 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 87
3 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 86
4 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 57
5 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 85
6 0446157747 USC CARE MEDICAL GROU… CAHPS_GRP… CAHPS for MI… 24
7 0446162697 ASSOCIATION OF UNIVER… CAHPS_GRP… CAHPS for MI… 59
8 0446162697 ASSOCIATION OF UNIVER… CAHPS_GRP… CAHPS for MI… 85
9 0446162697 ASSOCIATION OF UNIVER… CAHPS_GRP… CAHPS for MI… 83
10 0446162697 ASSOCIATION OF UNIVER… CAHPS_GRP… CAHPS for MI… 63
# ℹ 490 more rows研究の対象となっているのは組織だけど、各組織のデータは6つの行を跨いでいる。
どうやって一つの組織を一つの列にできる?
pivot_wider()pivot_wider()の主な引数:
cols どの列を使う(ワイドにする)names_from 列名として使用するロング形式の列名values_from 新しい列に配置される値を持つロング形式の列でや、やって見ましょう
# A tibble: 500 × 9
org_pac_id org_nm measure_title CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 0446157747 USC C… CAHPS for MI… 63 NA NA
2 0446157747 USC C… CAHPS for MI… NA 87 NA
3 0446157747 USC C… CAHPS for MI… NA NA 86
4 0446157747 USC C… CAHPS for MI… NA NA NA
5 0446157747 USC C… CAHPS for MI… NA NA NA
6 0446157747 USC C… CAHPS for MI… NA NA NA
7 0446162697 ASSOC… CAHPS for MI… 59 NA NA
8 0446162697 ASSOC… CAHPS for MI… NA 85 NA
9 0446162697 ASSOC… CAHPS for MI… NA NA 83
10 0446162697 ASSOC… CAHPS for MI… NA NA NA
# ℹ 490 more rows
# ℹ 3 more variables: CAHPS_GRP_5 <dbl>, CAHPS_GRP_8 <dbl>,
# CAHPS_GRP_12 <dbl>ふむ、NAが多い、行の数がまだ変わっていない。どうすれば良い・・
cms_patient_experience |>
pivot_wider(
names_from = measure_cd,
values_from = prf_rate,
id_cols = starts_with("org")
)# A tibble: 95 × 8
org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 0446157747 USC CAR… 63 87 86 57
2 0446162697 ASSOCIA… 59 85 83 63
3 0547164295 BEAVER … 49 NA 75 44
4 0749333730 CAPE PH… 67 84 85 65
5 0840104360 ALLIANC… 66 87 87 64
6 0840109864 REX HOS… 73 87 84 67
7 0840513552 SCL HEA… 58 83 76 58
8 0941545784 GRITMAN… 46 86 81 54
9 1052612785 COMMUNI… 65 84 80 58
10 1254237779 OUR LAD… 61 NA NA 65
# ℹ 85 more rows
# ℹ 2 more variables: CAHPS_GRP_8 <dbl>, CAHPS_GRP_12 <dbl>多くの場合、使いたいデータが複数のデータセット(データフレーム、あるいはファイル)に跨いで入っている
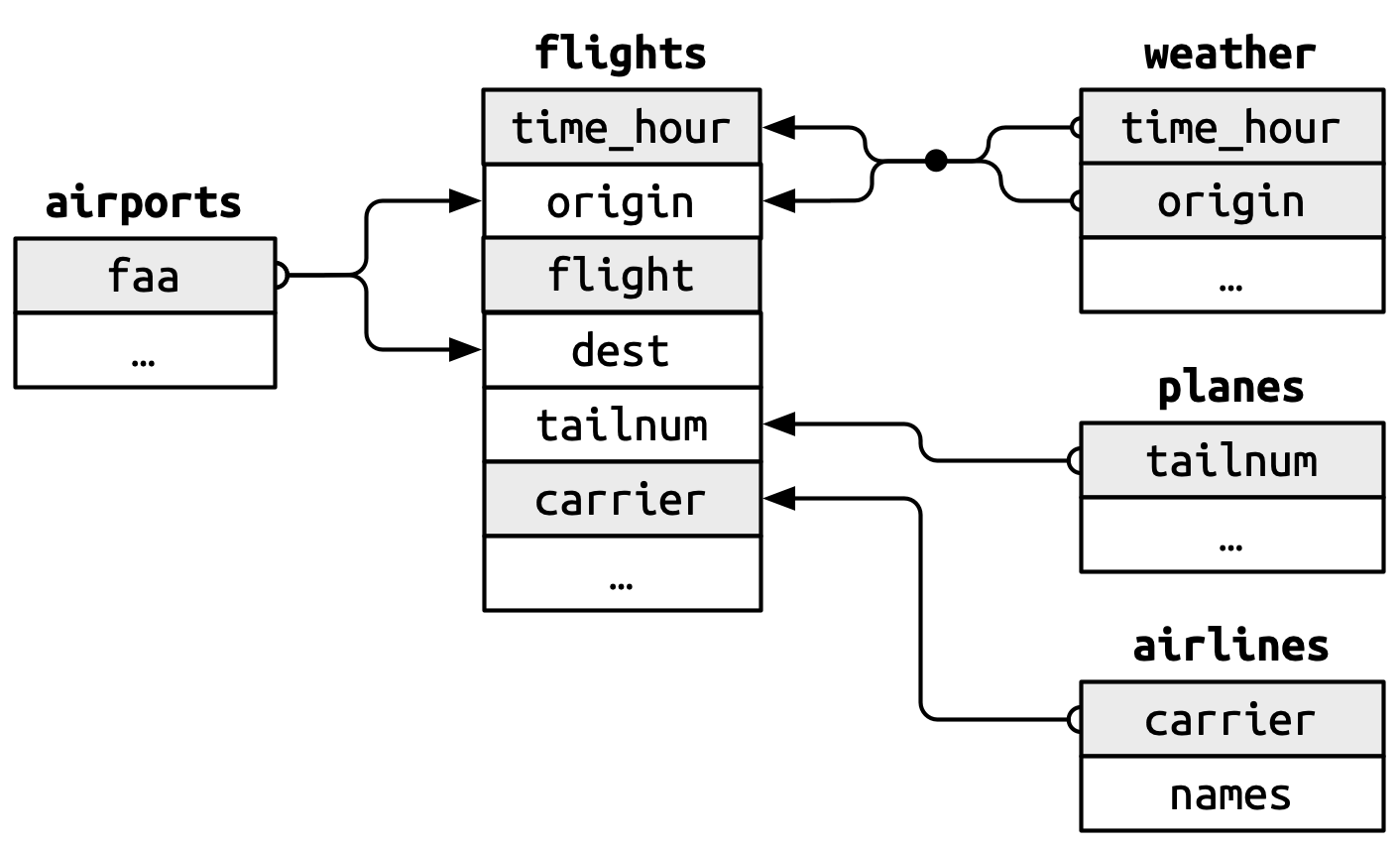
したがって、データの結合(join)を行う必要がある
airlinesには航空会社の名前のデータが入っている:
# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. どうやってこのデータをnycflights13と結合させることができるのでしょうか?
nycflights13は列の数が多いことを覚えていますか?
left_join()航空会社の名前を追加しましょう:
# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air …
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air …
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Ai…
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Air…
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air L…
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air …
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Air…
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet …
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Air…
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Ai…
# ℹ 336,766 more rows上のコードを走らせた際、このメッセージがありました:
Joining with `by = join_by(carrier)`つまり、それぞれのデータフレームが共通に持っている列です。これ「鍵」(Key)と呼ぶ。
共通に持っている列がないと、結合ができない。
上のコードは自動的に共通する列を鍵として使ったけど、手動で指定することもできる:
# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air …
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air …
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Ai…
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Air…
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air L…
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air …
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Air…
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet …
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Air…
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Ai…
# ℹ 336,766 more rows右側のデータの鍵が行を識別できる必要がある。それぞれのcarrierはデータに一回だけ出てくる
count()で確かめる(nが全て1になっている)
nycflights13パッケージに他のデータフレームがいくつかある:
planesのデータをflights2に結合することができますか?